Abstract
As subsymbolic Artificial Intelligence (AI) systems have become increasingly integrated into decision support tools, there is a consequent need for transparency and interpretability. While eXplainable AI (XAI) techniques offer valuable insights into model behavior, they often lack the formal rigor required for causal interpretation and verification – qualities inherent to symbolic AI. This paper presents a framework designed to bridge the gap between subsymbolic explanations and symbolic reasoning through the application of Multimodal Language Models (MLMs). Our approach combines the output of XAI methods with symbolic knowledge bases encoded in a logic programming language, enabling abductive reasoning and yielding causal interpretations of explanations produced over predictions. In our framework, MLMs serve as intersymbolic translators, converting visual or textual explanations into structured logical assertions that can be processed by reasoning engines for verification. Through this integration, we aim to enhance the interpretability of AI systems and promote the use of sound reasoning to increase the trustworthiness of the observed AI-based system.
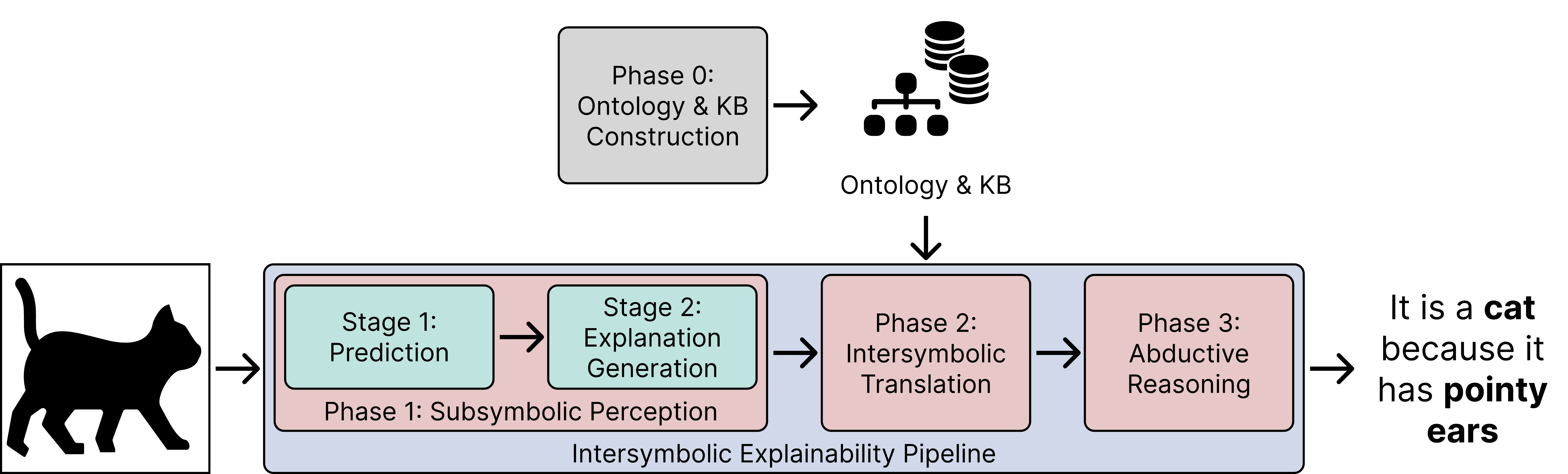
Method Overview
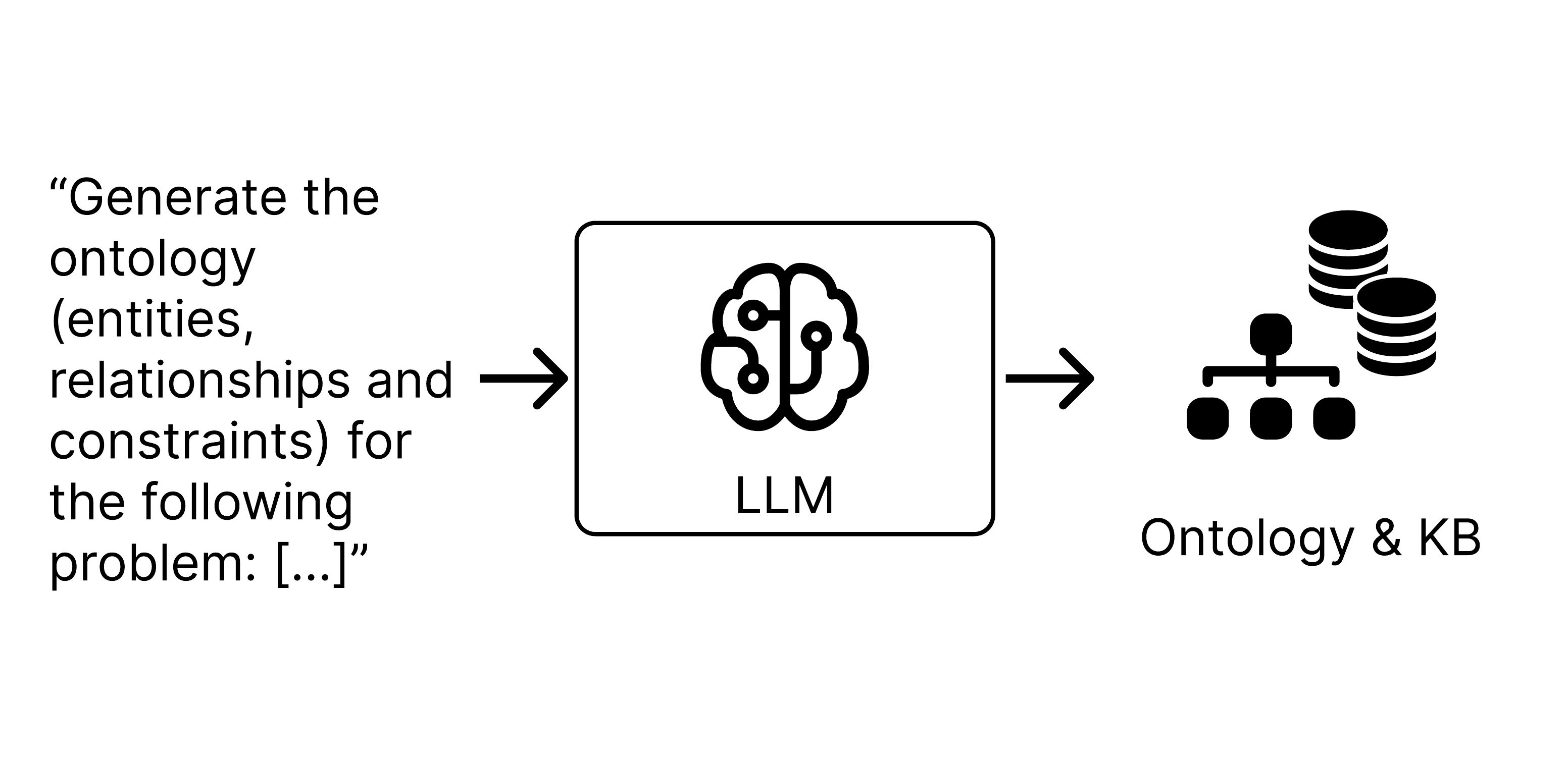
Phase 0: LLM-assisted Ontology and Knowledge Base Construction - Domain knowledge is elicited and encoded as ProbLog facts.
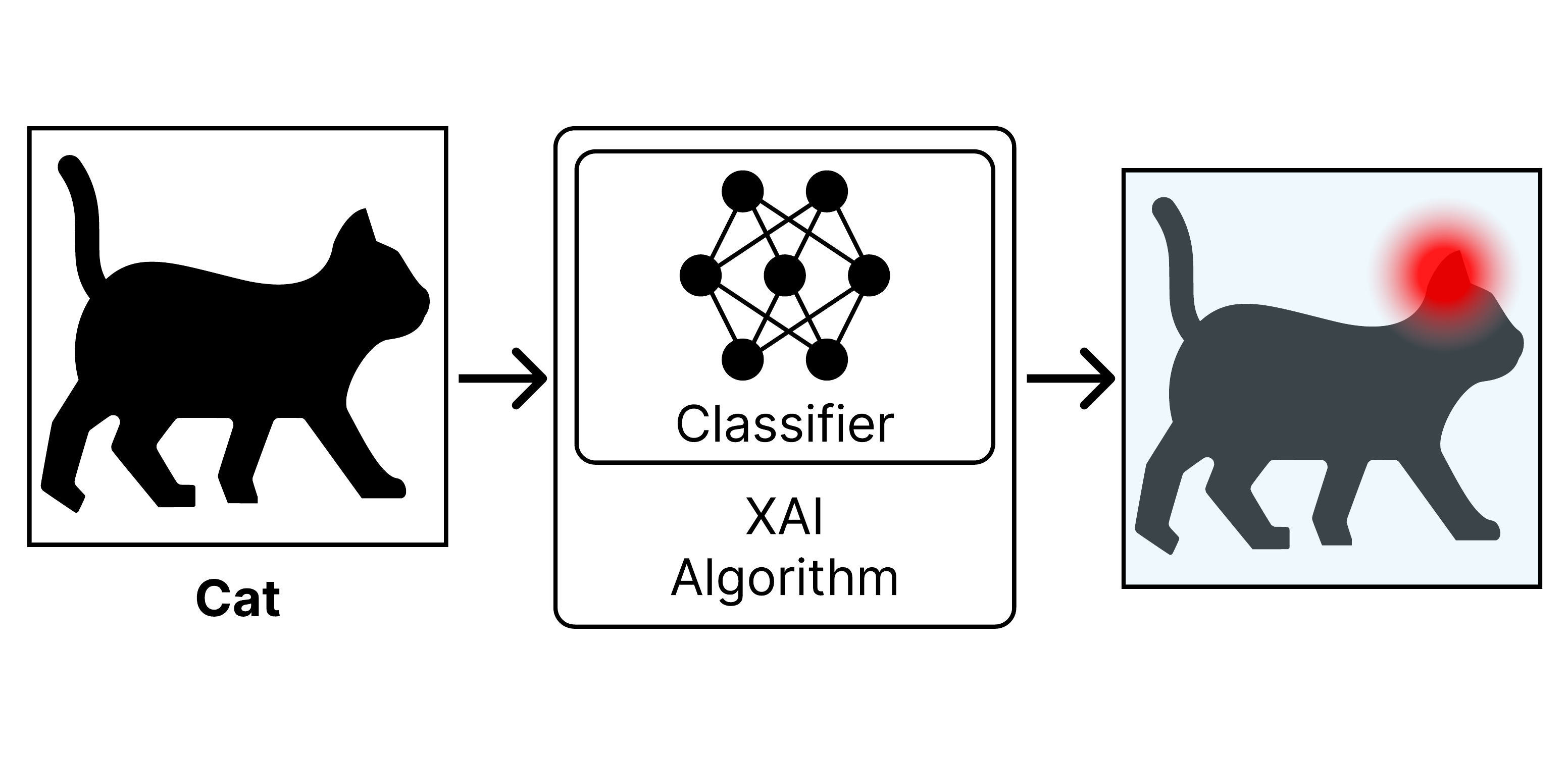
Phase 1: Subsymbolic Perception - CNN classification followed by Grad-CAM++ explanation generation.
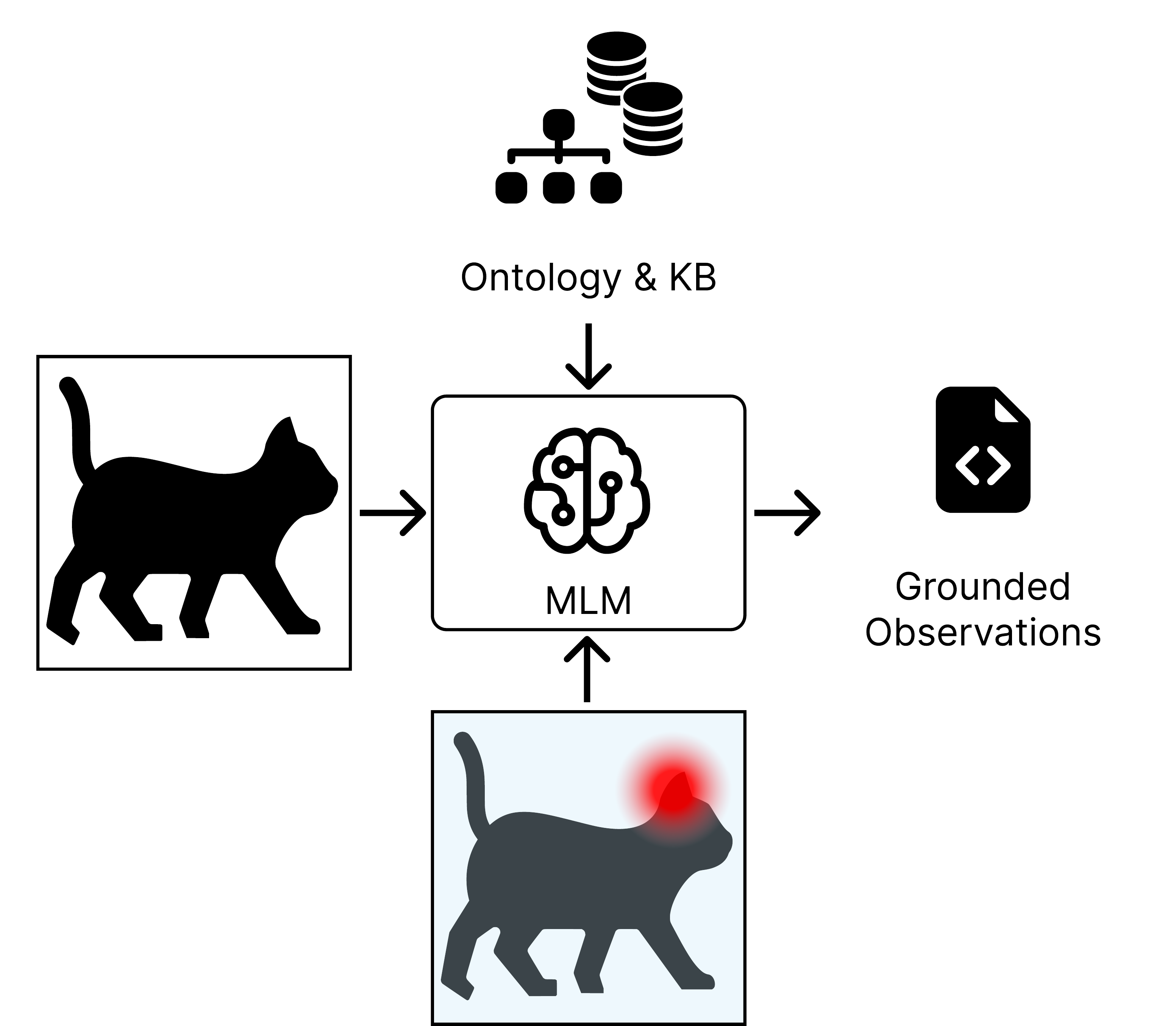
Phase 2: Intersymbolic Translation - MLM grounds visual features from heatmaps into probabilistic logic facts.
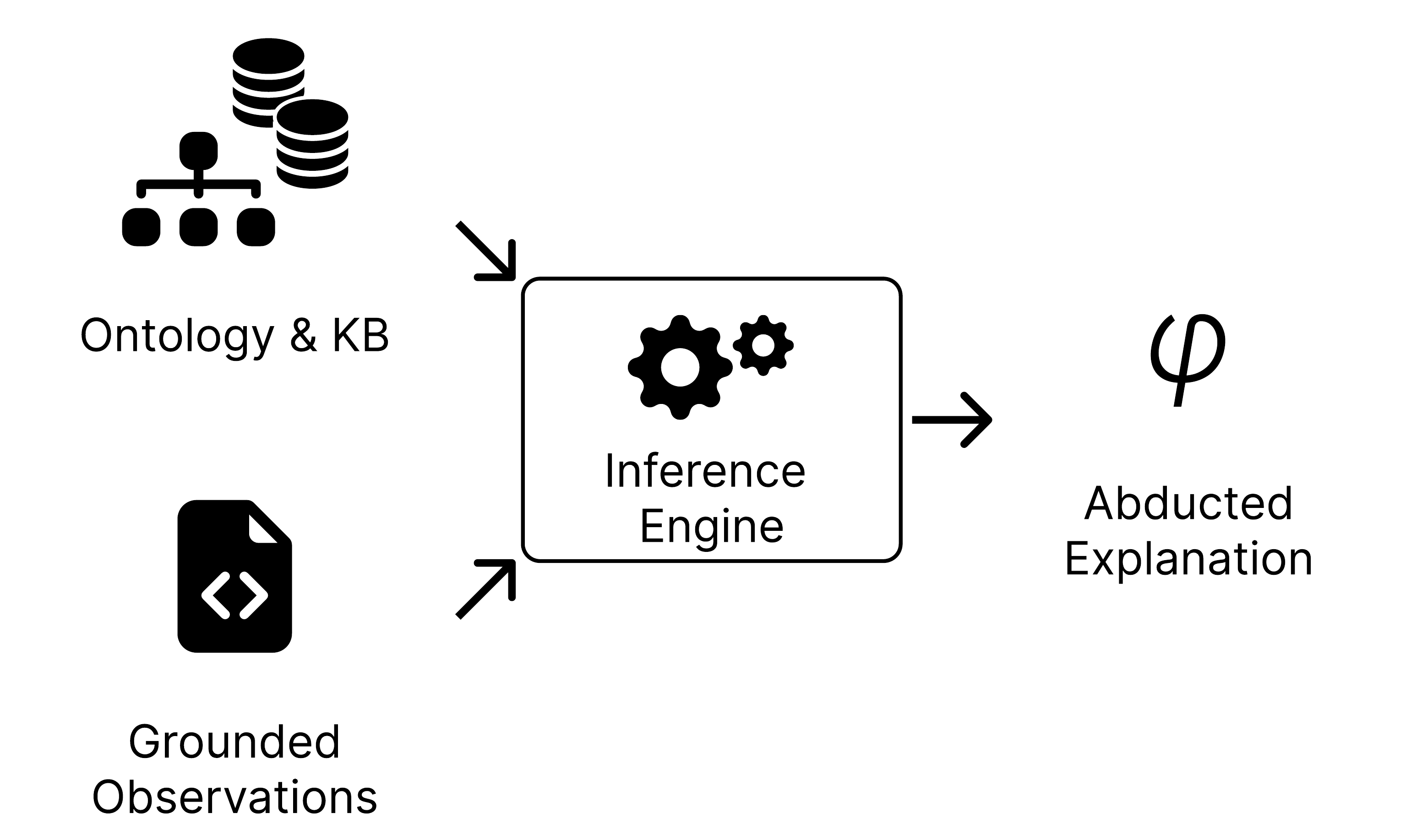
Phase 3: Abductive Reasoning - ProbLog inference engine computes the most probable explanation.
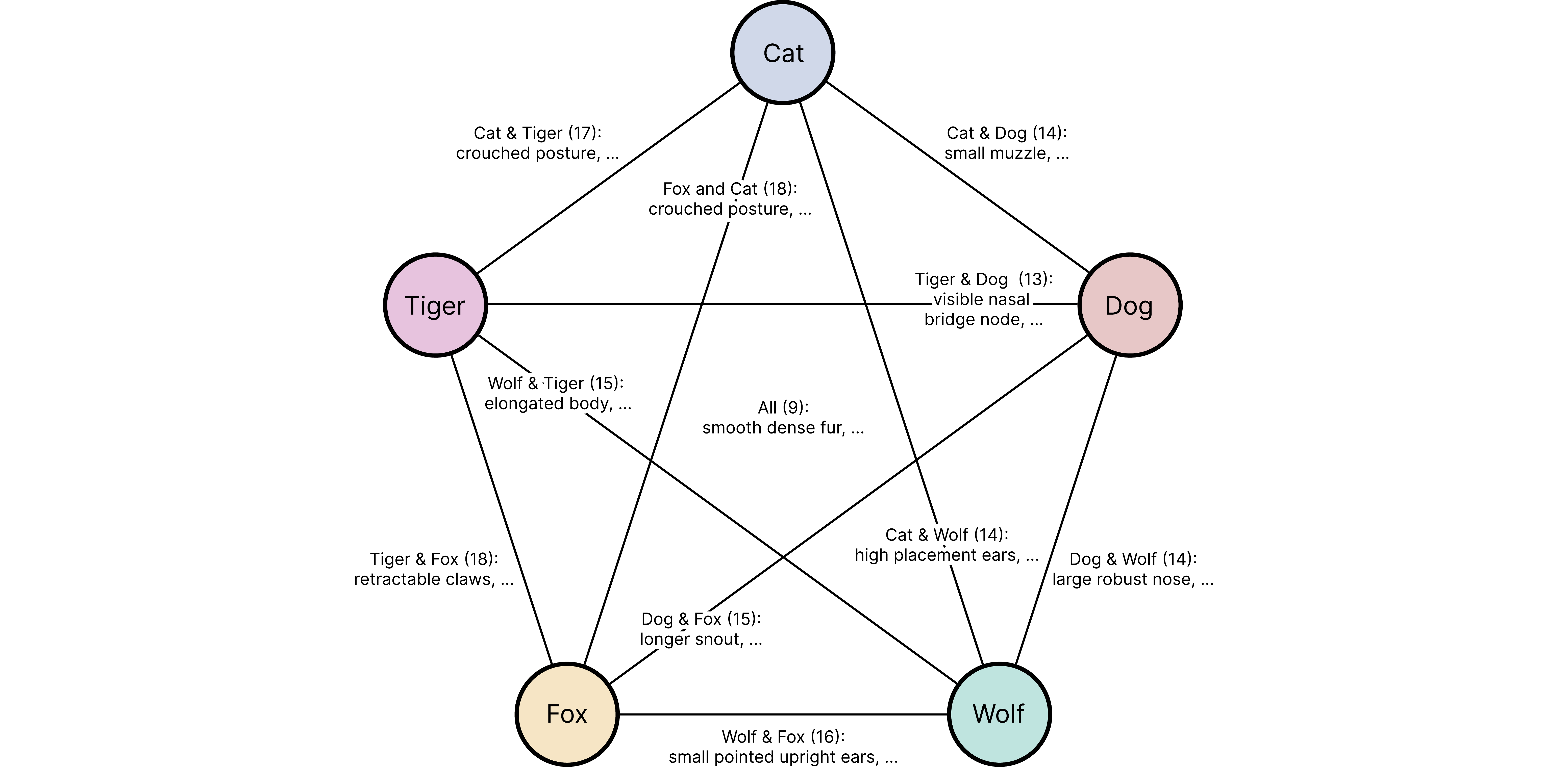
Feature Analysis: Cross-paired features from the grounding stage showing shared and unique discriminators across classes.
Experimental Results
We evaluated our pipeline on a custom dataset with Cat and Dog as in-distribution classes, and Fox, Tiger, and Wolf as out-of-distribution (OOD) classes.
| Ground Truth | Support | CNN Prediction | Symbolic Inference | ||
|---|---|---|---|---|---|
| P(Cat) | P(Dog) | P(Cat) | P(Dog) | ||
| Cat | 15 | 0.994 | 0.006 | 0.874 | 0.126 |
| Dog | 15 | 0.357 | 0.643 | 0.403 | 0.597 |
| Fox (OOD) | 12 | 0.717 | 0.283 | 0.795 | 0.205 |
| Tiger (OOD) | 12 | 0.893 | 0.107 | 0.665 | 0.335 |
| Wolf (OOD) | 12 | 0.461 | 0.539 | 0.063 | 0.937 |
Key Finding: The CNN struggled to distinguish Wolves from Cats (P=0.461 for Cat). However, our symbolic verification phase correctly identified that the visual evidence did not support the Cat classification, dropping the probability to 0.063. This demonstrates how abductive reasoning can detect and correct reasoning shortcuts in neural classifiers.
BibTeX
@inproceedings{Schuler2025Bridging,
title={Bridging Explanations and Logics: Opportunities for Multimodal Language Models},
author={Schuler, Nicolas Sebastian and Scotti, Vincenzo and Camilli, Matteo and Mirandola, Raffaela},
booktitle={International Symposium on Leveraging Applications of Formal Methods, Verification and Validation (AISoLA 2025)},
year={2025},
organization={Springer},
doi={10.5445/IR/1000184717},
url={https://github.com/NicolasSchuler/abduction-demo}
}